
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- java spring framework
- Code Presso
- 스프링 프레임워크
- 위치 기반 쿼리
- JPA
- AWS Developer
- NoSQL
- 대용량 아키텍처와 성능 튜닝
- Text Index
- STS
- Java
- 몽고디비
- Spring Framework
- AWS 자격증
- Amazon Web Service
- 쓰기 고려
- 조대협
- Jenkins
- iam
- 스프링
- spring boot
- Write Concern
- aws
- mongoDB
- EC2
- 자바
- 스프링 부트
- 읽기 고려
- 코드프레소
- Spring
- Today
- Total
개발과 기록의 조화
[MongoDB] MongoDB 구조, 기본 CRUD 명령어 본문
해당 게시물은 학습 및 기록 목적으로 작성되었습니다. 사실과 다른 내용이 있을 수 있으며, 오류가 있거나 궁금한 점은 댓글이나 dlaudtjr07@gmail.com 으로 메일 주시면 감사하겠습니다.

해당 게시물은 이전의 글과 이어집니다.
MongoDB 구조
MongoDB의 구조는 명칭 상으로 RDBMS와 확실하게 다르지만, 표로 비교해 보면 뭔가 비슷해 보이기도 합니다.
| RDBMS | MongoDB |
| Table | Collection |
| Row | Document |
| Column | Field |
| Primary Key | Object_ID Field |
| Relationship | Embedded & Link |
{
"_id":ObjectId("5e36caadd47bf50148322e9e"),
name: "MyoungSeok",
age: 25,
feel: "Happy",
address: ["Incheon" , "Geomam"]
}Collection은 Table과 같은 개념으로, Collection 내부에는 _id Field , Document, Field 를 포함하고 있습니다.
Document는 Row와 같은 개념으로, Document 내부에 여러 Field에 대한 하나의 데이터가 포함되어져 있습니다.
Field는 Column과 같은 개념으로, 한 Field에 대한 데이터가 포함되어져 있습니다.
Object_ID Field는 PK와 같은 개념으로, "_id" 의 이름을 가진 Key로 따로 설정을 해 주지 않을 시 Default로 String형 데이터가 임의로 삽입됩니다.
Embedded & Link는 MongoDB에서 적용되는 자식 객체가 단독으로 사용되지 않고 부모객체 내에서만 사용될 때 사용되는 Embed 옵션과 , 자식객체가 부모객체와는 별개로 단독으로 사용될 때 적용되는 Link 옵션이 함께 적용됩니다.
명령어
먼저 DB를 생성하면서 차례차례 하나씩 명령어를 학습해 봅시다.
DB 생성
db
명령어를 사용하면 현재 내가 사용중인 데이터베이스를 확인할 수 있습니다. 처음에는 그냥 'test'라고 나오네요.

새로운 데이터베이스를 만들어 봅시다.
use <DB이름>
명령어를 입력하면, 만들어져 있는 DB라면 그대로 사용이 되고, 없는 DB라면 새로 생성하면서 자동으로 사용하게 됩니다. 생성 후 다시 db를 입력해 봅시다.

ms라는 이름의 DB로 바뀐 것을 확인 할 수 있습니다.
현재 사용하고 있는 데이터베이스를 확인해 봅시다.
db.stats()

데이터 생성
user Collection을 만들어 봅시다.(본인은 이미 user Collection이 만들어져 있으므로 user2 Collection을 생성)
db.createCollection( "<Collection이름>" , {capped:<boolean>, autoIndexId:<boolean> , size:<number> , max<number> } )

capped옵션을 설정하면 Capped collection이 활성화됩니다. 고정된 크기를 가진 컬렉션으로 size가 초과되면 해당 컬렉션에서 가장 오래된 데이터를 덮어쓰게 됩니다. capped 옵션은 아래와 같습니다.
| Parameter | 입력 Type | 설명 |
| capped | Boolean | true 설정 시 Capped collection 옵션 활성화 , 활성화 시 size 입력 필수 |
| autoIndexId | Boolean | _id 필드에 index 자동 생성, 곧 사라질 옵션이니 그냥 알아만 두자 |
| size | number | 컬렉션의 최대 size를 byte 단위로 설정 |
| max | number | 컬렉션에 추가 가능한 최대 개수 설정 |
ms DB 안에 있는 user Collection 데이터를 입력해 봅시다.
db.<Collection이름>.insertOne( { (옵션)<_id : Field> , <Key:Field> } )
명령어로 데이터를 입력해 봅시다.

_id는 옵션입니다. 따로 설정해 주지 않으면 Default로 임의의 String값이 들어갑니다. 이제 저 데이터를 찾아봅시다.
db.<Collection이름>.find( { <Key:Field> } )

find안에 따로 데이터 값을 넣어주지 않으면 모든 데이터를 찾는다는 의미입니다. 우선은 데이터가 올바르게 들어갔으니 다른 데이터를 입력해 봅시다.
db.<Collection이름>.insertMany( [ { (옵션)<_id:Field> , <Key:Field>.... } ] )

본인은 다른 Collection info에 데이터를 새로 삽입했습니다. 이렇게 Collection이 생성되어져 있지 않아도 이름을 입력하면 자동으로 Collection이 생성됩니다.(capped 옵션은 설정되지 않습니다)
insertOne 명령어와는 다르게 {}괄호 안에 [](리스트) 형태로 들어갑니다. 2개 이상의 데이터를 입력하는 데 사용합니다.
위 데이터는 id를 따로 입력하지 않아서 Default로 생성된 값입니다. 데이터를 찾아봅시다.

위에서 입력했던 find 명령어입니다. 중괄호 안에 아무 데이터도 입력하지 않아서 모든 데이터가 출력되어졌습니다.
데이터 수정
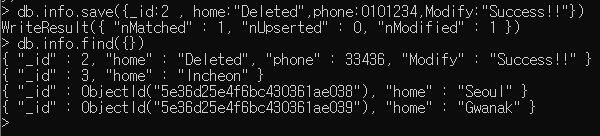
ID가 2번인 Home의 데이터를 부산으로 바꿔 봅시다.
db.<Collection이름>.update( { <조건Key> : <조건Field> },{ $set : { <대상Key> : <대상Field> } } )


update() 메소드는 특정 하나의 필드만 수정할 수 있다는 특징이 있습니다. 하지만 여러 필드를 한번에 수정하고 싶다면, save() 메소드를 이용하면 됩니다.
2번의 아이디를 가지고 있는 데이터를 수정해 봅시다. home은 인헌으로 수정하고 추가적으로 phone 필드를 추가해 데이터를 삽입해 봅시다.
db.<Collection이름>.save( { <Key> : <Field> } )

데이터를 조회해 보면

정상적으로 2번의 데이터가 수정된 것을 확인할 수 있습니다.
save()메소드는 insert 메소드와 같은 역할을 하지만, 확실한 차이가 있습니다. id의 존재 여부에 따라서 하는 행동이 서로 다릅니다.
insert() 메소드는 id가 똑같은 값을 저장하려고 하면 오류가 발생합니다.

반면에 save() 메소드는 똑같은 값을 저장하거나 없는 필드를 수정해도 그대로 덮어쓰게 됩니다. 하지만 이전 데이터는 사라지게 되겠죠.
데이터 제거
info collection에 있는 id값 3인 데이터를 제거합시다. 삭제 옵션은 home에 있는 데이터로 정의합니다.
db.info.remove( {( <criteria> , <justOne> ) } )


remove()메소드에는 두 가지 옵션이 있습니다.
| Parameter | 데이터 Type | 설명 |
| criteria | document | 삭제 할 데이터의 기준값, {}일 시 모든 데이터 제거 |
| justOne | boolean |
선택적 parameter이며, 값이 true일 시 1개의 document만 삭제됨 매개변수 생략 시 기본 옵션은 false이며, criteria에 해당되는 모든 document 삭제 |
위 삭제 명령어는 criteria를 이용한 기준 값을 정해준 명령어로서, 두 가지 실험을 해 보겠습니다. 우선 위에서 삭제한 데이터는 다시 save나 insert로 복구 후 진행합니다.

criteria의 값을 {}로 설정하고 justOne 옵션을 true로 지정하고 실행하면, 출력 기준 맨 위 데이터가 사라집니다. 즉, id가 2번인 데이터가 사라진 것을 확인할 수 있습니다.

criteria의 값을 {}로 설정하고 justOne 옵션을 false로 지정하고 실행하면, 남아있는 나머지 3개의 데이터가 모두 사라진 것을 확인할 수 있습니다. 물론 Default 값은 False이므로 따로 false를 넣어줄 필요는 없습니다.
마지막으로 ms DB를 제거합니다. DB를 제거하기 위해서는 use<DB이름> 명령어로 삭제할 db를 선택해야 합니다.
db.dropdatabase()

MongoDB의 기본적인 CRUD 명령어 학습을 마쳤습니다. 다음 게시물에서는 MongoDB의 연산자들에 대해서 알아보도록 하겠습니다.
해당 글은 코드프레소 DevOps Roasting 코스를 수강하면서 작성한 글입니다.
'Database > MongoDB' 카테고리의 다른 글
| [MongoDB] 쓰기 고려 (Write Concern) (0) | 2020.02.03 |
|---|---|
| [MongoDB] 읽기 고려 (Read Concern) (0) | 2020.02.03 |
| [MongoDB] 위치 기반 쿼리 (0) | 2020.02.03 |
| [MongoDB] 텍스트(TEXT) 인덱스 (0) | 2020.02.03 |
| [MongoDB] MongoDB 개념 및 설치 (0) | 2020.02.03 |



